Protocol Buffers 编码
Protocol Buffers 编码
reference:
本文翻译自官方文档,补充了部分前置知识与帮助理解的示例。
简介
Protocol Buffers (a.k.a., protobuf) are Google's language-neutral, platform-neutral, extensible mechanism for serializing structured data.
Protocol Buffers 是Google由推出的,跨语言、跨平台的用于序列化数据结构的可拓展机制 / 协议。
序列化格式
Protobuf的编码基于变种的Base128,下面先简单介绍Base64,Base128以及ZigZag编码。
Base64编码
reference: https://www.zhihu.com/question/585411183
Base64编码的设计初衷是为了让数据在设备间传输时,目标机器能够正确地“理解”字节流中的内容:字节流中的内容均可以通过ascii字符正常显示。
举例:
// 输入下述字节流
0b10100010 0b00001001 0b11000010 0b11010011
// 以6bits为单位进行分组,并在最后补0
0b101000 0b100000 0b100111 0b000010 0b110100 0b110000
// 接着每一组6bits都在高位补0
0b00101000 0b00100000 0b00100111 0b00000010 0b00110100 0b00110000附图Base64编码对照表
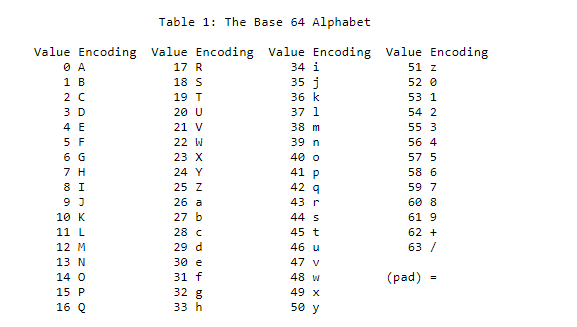
最后在按照6bits一组划分后,再以(pad)=
根据4字节对齐,得到最终编码结果。编码结束后,任意字符流就都能用数字、字母以及
+ / = 符号表示了,这些都是可以被正常显示的 ascii
字符,ascii字符在绝大多数计算机和操作系统都被良好支持了,可被正确地复制、传播、解析。
*到这里就能意识到,Base64编码并不是自己以前想的什么“Based on 64”,而实编码后的结果仅有64个可视的ascii字符。
Base128编码
Base64编码存在的一个问题就在于对每6比特进行补零,这样在最理想的情况下(即无末尾补零,也无末尾4字节padding)也只有75%的空间利用率。
按照Base64的思路,可以将字节流按照7bits进行分组,然后同样对低位补0,补足一组8bits,再进行末尾4字节padding。
但是问题在于,使用Base128会导致实际需要的字符有128+1个,而ascii字符集只有128个可用字符。同时,ascii字符中还包含了一些不可正常打印的控制字符,所以Base128未能完全替换Base64,而是以一些变种存在。
ZigZag编码
ZigZag编码法将正数与负数穿插排列,一个用例是在Base128Varint中的使用,用于避免负数带有过多的高位1。
- 所有的正数
p将被编码为2 * p(全体偶数) - 所有的负数
n将被编码为2 * |n| - 1
给出一个 ZigZag 法下的例子:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| … | … |
| 0x7fffffff | 0xfffffffe |
| -0x80000000 | 0xffffffff |
给出 ZigZag
法的位计算公式,对32位带符号数n有(注意这里的n使用是负数的二进制补码表示):
(n << 1) ^ (n >> 31)对64位带符号数有:
(n << 1) ^ (n >> 63)Base128 Varints
*确实是Varint,表示边长int,不是Variant
Varints are a method of serializing integers using one or more bytes. Smaller numbers take a smaller number of bytes.
特性
- 只能对部分类型的数据进行编码,不适用于所有字节流
- 编码后的字节可以不存在于ascii表中,因为应用场景不同,不需要考虑是否能够正常打印
编码方式
对Base128 varint处理后的每个字节,低7位用于储存数据,最高位(most significant bit,简称msb)用于表示此字节后续是否还有内容,当msb为1时表示后续还有数据,为0时表示当前字节已是最后一字节。
// 以int类型数值300为例
0b100101100 0x012C
-> 0b[1]0101100 0b[0]0000010protobuf的varints最多可以编码8字节数据,因为现代计算机最高也是支持处理64位整型。
支持的数据类型 wire type
protocol buffer 的消息是一系列的键值对,而序列化的binary信息使用字段序号(field number)作为key,每个字段的名字和声明类型(指在特定语言中的类型,而不是wire type,wire type是可以在binary信息中找到的)只有在解码端可以通过消息体的类型定义(.proto,或.proto生成文件)获得。
当信息被编码时,每一个键值对都被转换为一条 记录(record),包含下述内容:
- wire_type
- 字段序号(field number)
- 有效负载(payload)
每个wiretype都告诉解析器(parser)后续的负载有多大,或者说后续的负载该如何解析。
支持的六种wire_type如以下所示:
| ID | Name | Used For |
|---|---|---|
| 0 | VARINT | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | I64 | fixed64, sfixed64, double |
| 2 | LEN | string, bytes, embedded messages, packed repeated fields |
| 3 | SGROUP | group start (deprecated) |
| 4 | EGROUP | group end (deprecated) |
| 5 | I32 | fixed32, sfixed32, float |
每条记录中的标签(tag)都使用字段序号,以及wire_type通过以下公式计算得到,这个标签本身也使用VARINT格式。也就是说每个字段的起始varint,低三位表示wire_type,而剩余内容表示字段序号。
(field_number << 3) | wire_type可以得到tag内容为 field_number * 8 + wire_type
的二进制表示
举例有下述输入
0x0008 0x9601,以小端考虑,读取前三位就能得到wire_type为0,再读取高位内容便能得到字段序号为1。接下来以wire_type
0类型VARINT解析后续内容0x9601,边能得到payload内容为数值150。
最大支持的 field_number 时?值得研究一下。
更多整型类型
Enum & Bool
枚举和布尔类型都被作为int32处理,他们也使用VARINT wire_type 进行编码
Signed Integers
varints 被视作无符号的整型,所以在处理带符号整型有不同的行为:如果带符号数使用二进制补码表示负数,负数的最高位将总是1。如果直接按照上述的方式转换为varint,负数将占用整整10个字节,这也是varint的最大长度。
// 举例数值sint64 -5的二进制补码表示负数
// 原码(little-endian high -> low)
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101
// -5 的二进制补码
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111011
// 按7bits分组
1 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111011
// 分组8bits补全,10 bytes in total
[0]0000001 [1]1111111 [1]1111111 [1]1111111 [1]1111111 [1]1111111 [1]1111111 [1]1111111 [1]1111111 [1]1111011(复习一下,使用二进制补码取负数的方式为:相应正数取二进制反码 + 1 / 或者 ~0 - (positive) + 1)
sintN 使用 “ZigZag”
法取代二进制补码进行负数的编码,这种编码法将正数与负数穿插排列,如此一来,负数的编码结果就不会因为高位的1占用过多字节了。
当 sint32 和 sint64
解析后,值会被重新解码会原先的带符号(二进制补码)形式。需要注意的是,在
protoscope 中,使用 z
后缀即表示该值使用ZigZag法编码,例 -500z == 999 。
非变长数字
非变长的数值类型很简单,double 与 fixed64
都使用 wire_type I64,对应的 float 与
fixed32 都使用 wire_type
I32,前者解析器将读取8字节数据,对应的后者读取4字节数据。
使用i64后缀,或者i32后缀来将数值标记为对应的wire_type。
Scalar Value Types
see https://protobuf.dev/programming-guides/proto2/#scalar
长度分割记录 Record
wire_type(2) 为类型 LEN,在tag后存了一个 varint 表示的整数表示后续有多少字节内容。距离字符串”testing”,编码为以下结果。
12 07 [74 65 73 74 69 6e 67]tag 中的 12
转换为二进制表示为00010 010,有wire_type
2,再往后读一字节即可得到后续字串的长度为7字节。
同样的, bytes 类型字段也使用这种形式进行编码。
嵌套消息体
子消息体同样使用 LEN wire
type。子消息体的编码结果会如同上述字串的内容存储在varint长度标志后。这同样要求了通信双端对于消息体的结构要有认知,否则就只知道字节数,而不知道如何应当解析(反序列化)为什么对象。
可选与重复元素 Optional and Repeated
对于Optional字段,如果字段未被设置,那么字段将在编码时被跳过。
对于Repeated字段,编码时将会为这个集合中的每一个元素编码一个相同的tag。同时留意,同一个repeated字段的元素在编码结果中不一定连续,他们只需要保证相对位置不出错。
如对以下结构体
message Test4 {
optional string d = 4; // 设置为 "hello"
repeated int32 e = 5; // 设置为 {1, 2, 3}
}则编码结果可能为
4: {"hello"}
5: 1
5: 2
5: 3也可能为
5: 1
5: 2
4: {"hello"}
5: 3Oneofs
标识为Oneofs的字段间共享存储空间,设置其中的任一字段将清空其他字段内容,但除此之外并不影响编码逻辑,与上述内容一致
Last One Wins
一般来说,编码的信息中不应该出现非 repeated 字段的重复实例,但Parser通过提供Merge方法处理了这种情况,这也让合并多条信息成为可能。
Parser的Merge行为准则是接收最后一次的值结果,具体行为:
- 值类型字段,后来的覆盖前面的
- repeated 字段,内容将被连接
- 嵌套消息体,递归执行Merge操作
此规则的直接结果是两条消息的字节流连接后进行解码,与各自解码后再对结果实例进行Merge操作,将得到一样的结果,即
MyMessage message;
message.ParseFromString(str1 + str2);等同于
MyMessage message, message2;
message.ParseFromString(str1);
message2.ParseFromString(str2);
message.MergeFrom(message2);Packed Repeated Fileds
除 string bytes 外的任何 scalar type(可简单理解为值类型) 可被声明为
packed。proto2 中 packed 需要显式使用 [packed=true]
声明,proto3中为默认值。
packed 的 repeated 字段不再每个元素独立一条记录,而是编码到同一条
LEN
记录中。解码时会将长度标识符后续的字节流一个一个按照声明的类型进行解码,下一元素的起始位置取决于前一元素的长度。
举例下述结构体,其中字段 f 填充值为 3,270,86942
message Test5 {
repeated int32 f = 6 [packed=true];
}可以得到有以下编码结果
3206038e029ea705 // hex
3206 03(3) 8e02(270) 9ea705(86942)
00110(field_number=6) 010(LEN) 0000 0110(length=6bytes) 0000 0011 ...注意尽管在编码的结果中,声明为packed的同一字段不应重复出现,但parser依然视其为合法输入,且需要处理此情况。处理方式为将重复出现的 key-value pair 中value内的元素相连组合。
同时,parser需要支持在消息体字段被声明为packed下,也能解析接收到的非packed字节内容。反之要求仍然成立。通过如此要求parser,使用者在不破坏前向、后向兼容性的情况下,向现有的字段新增或去除 packed 标记。
Maps
maps常被用于字典/映射,Maps实际是特殊的repeated 字段,考虑将
key=value pair 作为嵌套结构体Entry,然后使用 reapted 属性声明,编码为
LEN 类型的连续记录即可。
举例结构体
message Test6 {
map<string, int32> g = 7;
}将被编码为
message Test6 {
message g_Entry {
optional string key = 1;
optional int32 value = 2;
}
repeated g_Entry g = 7;
}考虑非 packed 的编码结果为:
[7|LEN][single_entry_length]{[1|LEN][length][key][2|VARINT][value]}
[7|LEN][single_entry_length]{[1|LEN][length][key][2|VARINT][value]}...map 同样可以声明(或默认为)packed。
字段顺序 Field Order
.proto
文件并没有对字段序号的顺序进行要求,且顺序并不影响消息体的序列化行为。
消息体被序列化时,序列化器并不能以确定的顺序对已知的、或未知的字段进行写入(序列化),这取决于具体实现。因此,protol buffer 的序列化器必须在任何的读入顺序下都能够解析字段。
影响 Implications
- 不要假定序列化信息的字节输出是稳定的。对于那些拥有一个 bytes 字段用于携带另一个消息体的大消息体特别要注意这点。
- 对同一个消息体实例的多次序列化操作,并不保证能够有相同的字节输出,即序列化操作并不拥有确定性。
- 确定性只有在同一个版本的protocol buffer 可执行程序下可以办证,不同版本间可能有不同(原文为“Deterministic serialization only guarantees the same byte output for a particular binary”)。
- 因此有 protocol buffer 的消息体实例 foo,其复数次
SerializeAsString()输出,以及相应的Hash/CRC结果等均不能保证相等 - 在下述情景中,逻辑相等的 protocol buffer 消息体实例
foo与bar可能有不同的序列化输出:- 对
bar进行序列化的服务器使用了另一种语言的 proto实现 - 对
bar进行序列化的服务器更新了 proto 实现 - 对
bar进行序列化时,一些新增字段被处理为 unknown bar中存在非确定性字段bar中存在 bytes 类型字段,其内容为另一个消息体的序列化结果foo与bar是多个相同消息体实例以不同顺序相连接的结果
- 对
编码大小限制
序列化结果必须小于 2GiB,许多 proto 实现会拒绝序列化,或者解析超过这个限制的消息体。